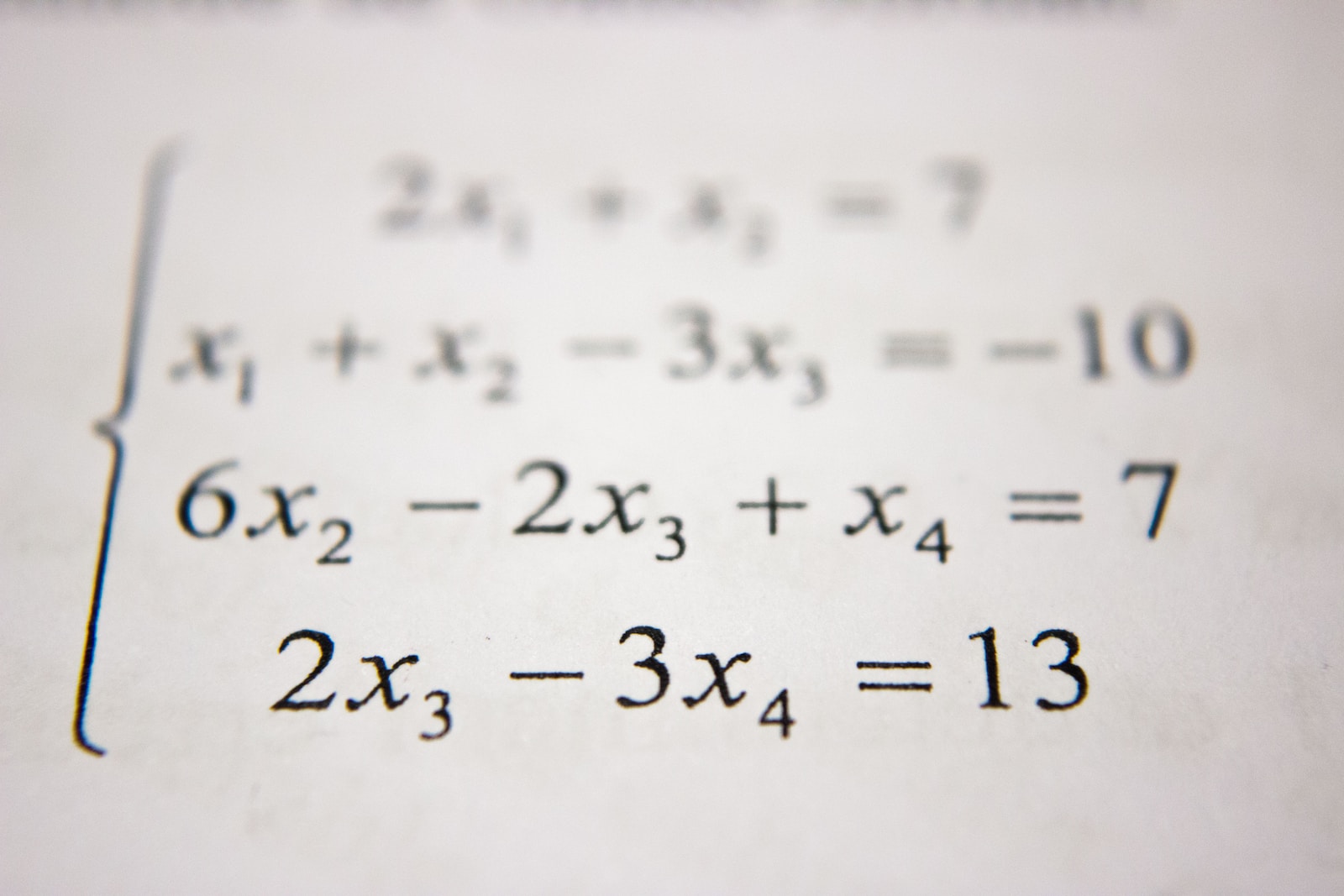What is liberal arts math?
Introduction Mathematics is often viewed through the lens of engineering and science, but what about those who tread paths less quantitatively rigorous? Liberal arts math provides an engaging alternative, tailored for students outside the STEM fields. This article delves into what liberal arts math entails, highlighting its relevance and value in a liberal arts education. … Read more